In our recent EMNLP 2025 paper, we investigate a subtle but impactful phenomenon in large language models: where you place your demonstration examples in a prompt significantly affects model performance.
The Setup
In-context learning (ICL) involves providing a few examples (demonstrations) in the prompt to guide model behavior — without any gradient updates. A standard prompt looks like this:
Input: "The movie was fantastic!" → Sentiment: Positive
Input: "I hated every minute." → Sentiment: Negative
Input: "What a delightful surprise!" → Sentiment: ???
The implicit assumption has been that the model weighs all demonstrations equally. Our work challenges this assumption.
What We Found
Our large-scale evaluation across multiple LLMs and tasks reveals that demonstrations placed earlier in the context window tend to exert stronger influence on predictions than those placed near the query. This primacy bias is distinct from the well-known recency bias and varies significantly by model family and task type.
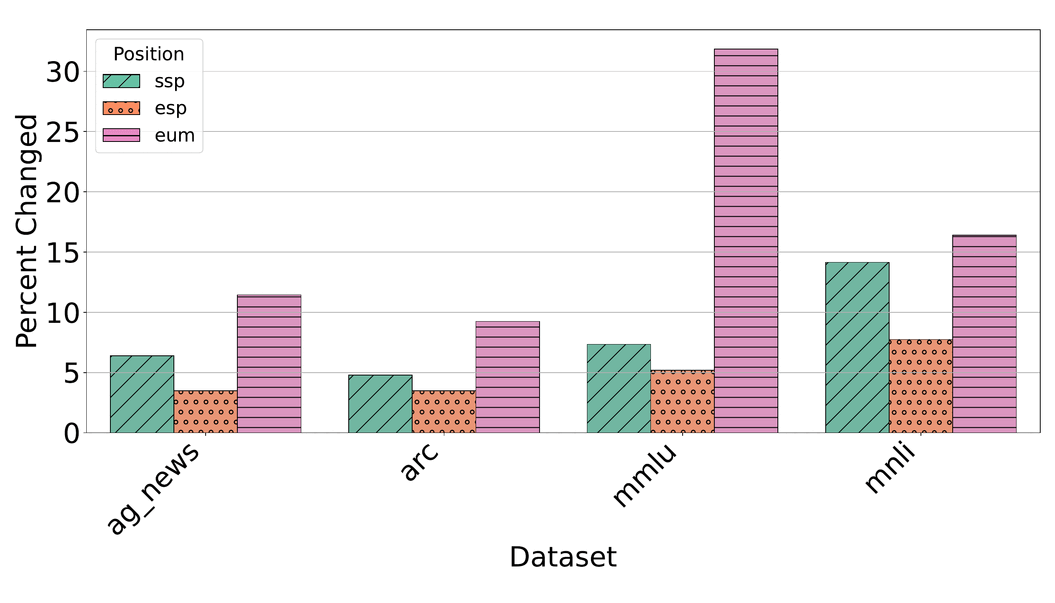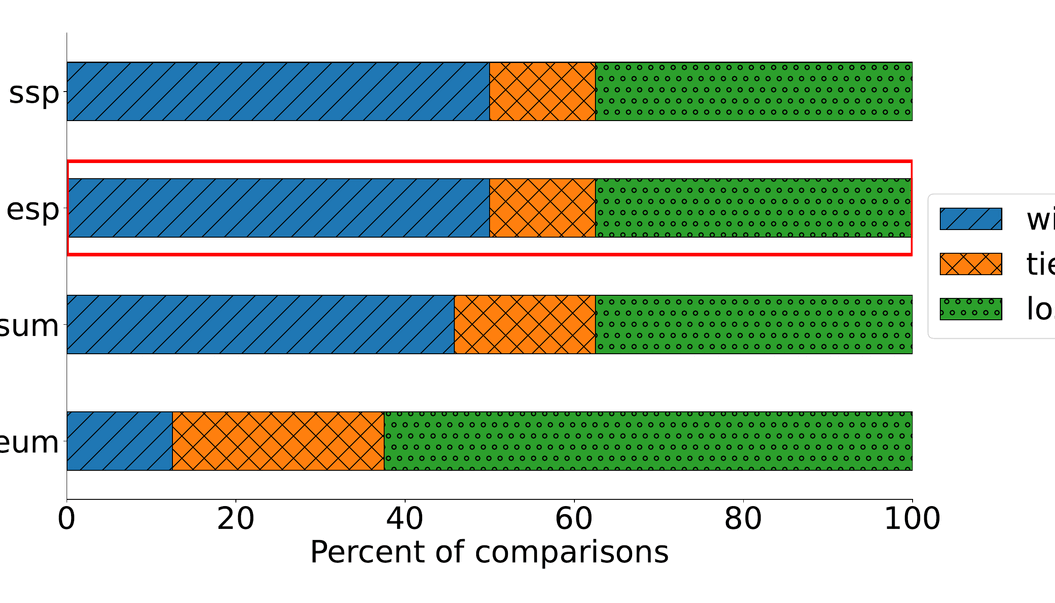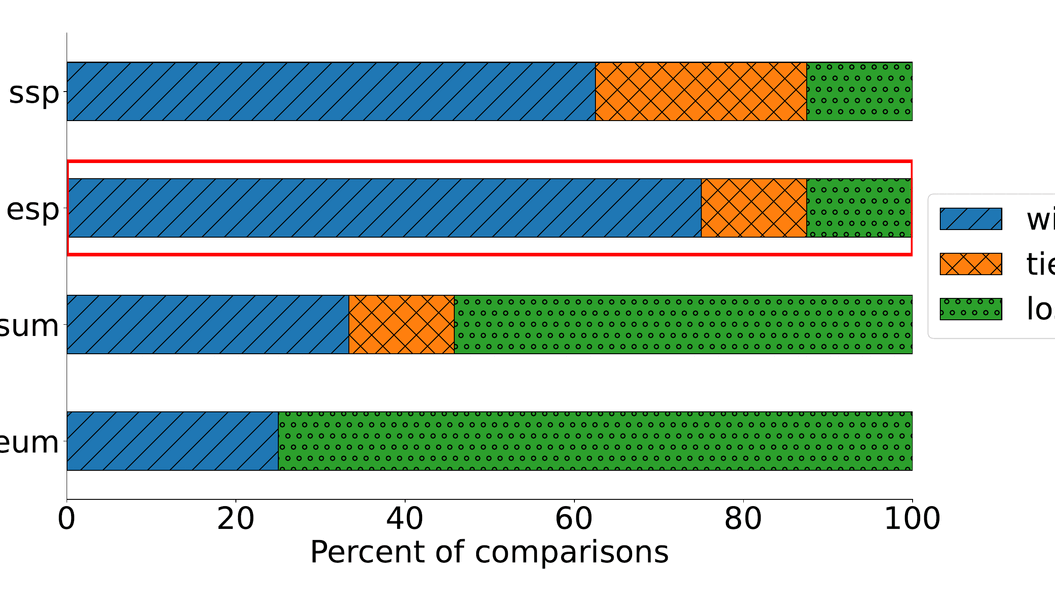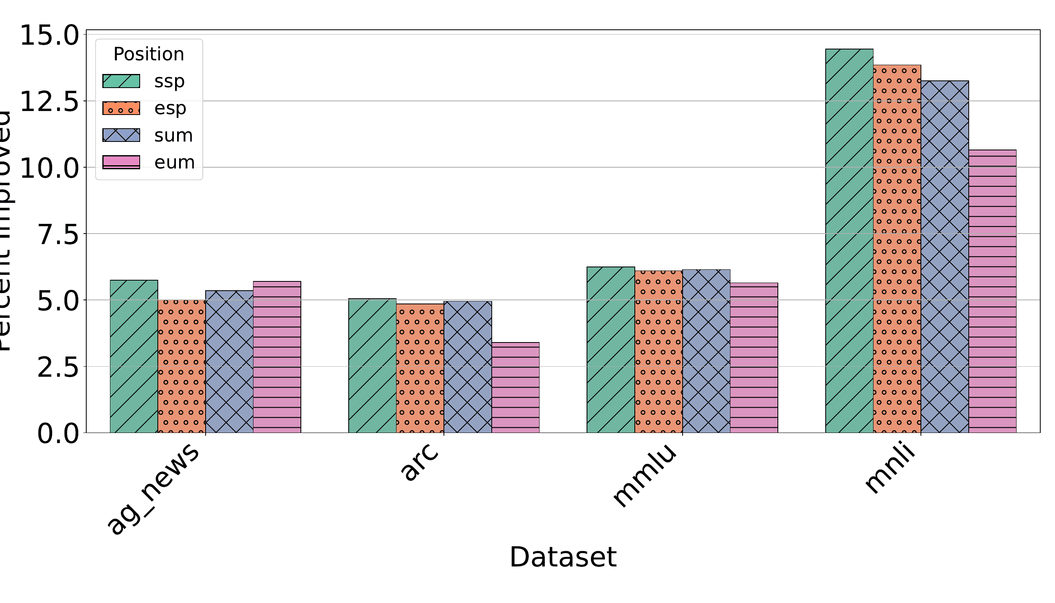
Concretely, we find:
- A swing of 5–8% in accuracy from demo reordering alone on classification tasks
- Primacy effects are stronger in smaller models; frontier models show more uniform weighting
- The effect is amplified when demonstrations span diverse label categories
Practical Implications
Based on our findings, we distill a set of prompt-design recommendations:
- For shorter contexts: Place your most informative or representative examples first.
- For longer contexts: Distribute diverse demonstrations throughout to dilute positional effects.
- For few-shot classification: Be intentional about the label distribution near the beginning of your prompt.
Looking Forward
This work motivates our follow-up project, Flip-Rate No More, which develops position-aware controllers to actively mitigate positional sensitivity — making ICL more robust regardless of how demonstrations are arranged.